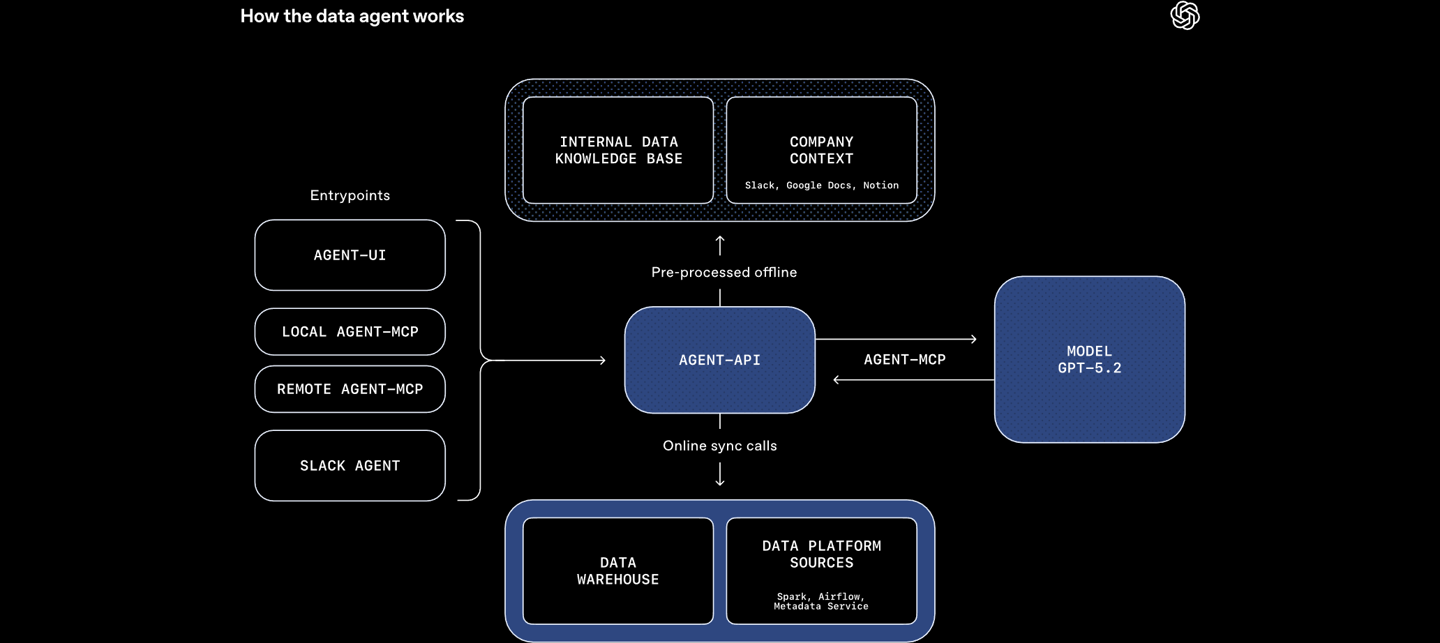
OpenAI首次对外披露为GPT-5.2配套打造的专用内部分析工具,该工具具备处理超过600PB海量数据的能力,并全面支持自然语言指令操作,为研究人员与开发者在大规模模型分析与洞察提取上提供前所未有的便利与效率。这一突破性工具的亮相,不仅展现了OpenAI在模型迭代与数据分析基础设施上的深厚积累,也凸显其在应对超大规模AI系统复杂性时的技术实力。
据介绍,该分析工具专为GPT-5.2的训练与运行数据构建,能够直接对涵盖文本、代码、结构化信息及多模态内容的庞大数据湖进行高速检索与深度解析。600PB的数据规模相当于数十亿份书籍的信息量,囊括模型迭代过程中的参数变化、训练样本特征分布、推理结果统计以及异常案例回溯等关键维度。工具内置分布式计算架构与高效索引机制,使原本需要数周才能完成的跨数据集关联分析,在数小时甚至分钟级完成,大幅压缩研究与调试周期。
自然语言交互是该工具的另一核心亮点。用户无需编写复杂查询语句或脚本,可直接用日常语言提出问题,例如“找出上周模型在逻辑推理任务中错误率最高的三类场景”或“比较不同版本在长文本生成连贯性上的差异”,系统便能自动解析意图、匹配相关数据并执行分析,最终以可视化图表或结构化报告呈现结果。这种交互方式显著降低了技术门槛,使跨学科研究者、产品经理乃至非技术背景的业务人员都能参与到模型行为的洞察与优化之中。
OpenAI表示,该工具的研发初衷是为了让GPT-5.2的开发与迭代更加透明与高效。面对日益庞大的模型规模与复杂的训练过程,传统分析方法已难以及时捕捉细微的性能波动与潜在问题,而新工具通过融合大规模数据处理与自然语言理解,实现了对模型全生命周期数据的即时探查与因果追溯。这不仅有助于快速定位影响生成质量的因素,也为安全对齐、偏见缓解与能力评估提供了更精细的依据。
在技术层面,该分析工具整合了OpenAI自研的高速向量检索引擎、多模态特征融合算法以及基于大模型的语义解析模块,确保在面对跨域异构数据时仍能保持高精度与低延迟。它还支持自定义分析流程与自动化报告生成,研究团队可将常用分析模式固化为模板,在后续项目中一键复用,进一步提升协作效率。
OpenAI此次发布的GPT-5.2内部分析工具,以超600PB数据处理能力和自然语言交互重新定义了大模型研发的分析范式。它不仅为GPT-5.2的持续进化提供坚实支撑,也为整个AI行业在面对超大规模模型时如何进行高效、直观的数据洞察设立了新标杆。未来,随着工具在内部使用的成熟,OpenAI或考虑将其部分能力以受限形式开放给合作伙伴与研究机构,共同推动大模型研发与分析方法的进步。