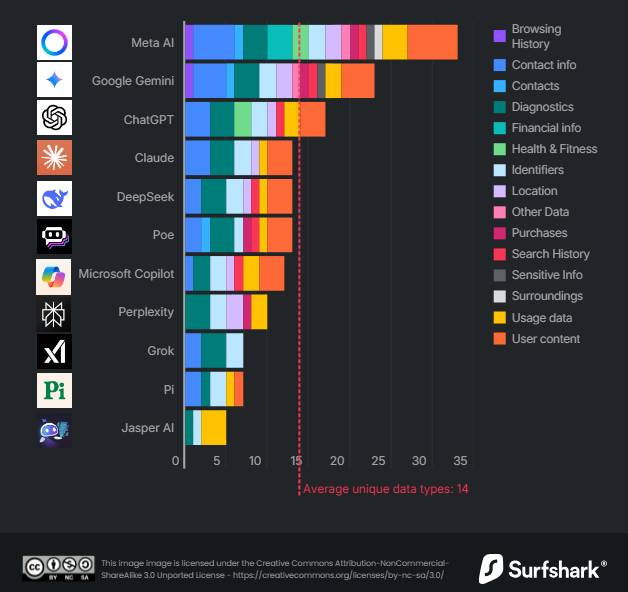
一份最新的安全研究报告警示,主流AI应用平均采集高达14项用户数据,存在显著的“AI偷窥”隐私风险。这些被采集的数据范围广泛,可能包括输入提示词、生成输出内容、对话历史、设备信息、位置数据、使用频率、甚至是通过摄像头、麦克风获取的周边环境信息。其采集机制通常隐藏在用户服务协议与隐私政策中,用户在享受免费或便捷服务时,往往无意中授权了广泛的数据收集。这些数据不仅用于改进模型,也可能用于用户画像分析、个性化广告,甚至被共享给第三方。
这种大规模数据采集行为对个人隐私与数据安全构成严峻挑战。从个体层面看,用户的偏好、观点、创作乃至生活片段被持续记录和分析,可能形成极其精准的数字画像,用于操纵性营销或影响决策。当敏感信息(如健康咨询、财务规划、私人对话)被采集时,一旦发生数据泄露,后果不堪设想。从社会层面看,集中化的海量行为数据可能强化平台权力,加剧“监控资本主义”模式,并可能被用于社会评分或歧视性定价。报告警示,当前用户对此风险的认知严重不足,而监管往往滞后于技术实践。
面对“AI偷窥”问题,当前的适用讨论正推动技术、法律与用户觉醒三方面的应对。技术趋势包括开发更强大的本地化/边缘计算AI模型,减少数据上传需求;采用差分隐私、联邦学习等技术,在保护个体数据前提下进行模型训练;以及推广数据最小化收集原则。法律层面,全球各地正在制定或完善针对生成式AI的数据保护法规,要求更透明的数据告知、更严格的用户同意机制以及赋予用户删除权。对用户而言,提升数据隐私意识、审阅权限设置、选择信誉良好的服务商至关重要。平衡AI创新与隐私保护,将是数字社会长期的基础性课题。
责任编辑:科技中国
点击查看全文(剩余0%)



